Pemula Wajib Kenali Exploratory Data Analysis (EDA) dalam Data Science


Belajar data science tidak hanya tentang teori, tapi juga harus terjun langsung menggunakan real-world data. Dengan begitu, pemahaman terhadap proses analisis data, pencarian insight, serta pembuatan machine learning menjadi lebih mudah.
Ketika melewati proses-proses tersebut, akan ditemukan tahapan Exploratory Data Analysis (EDA), yang tergolong krusial dalam pengolahan data. Kesimpulan itu terungkap dalam event DQLab yang diselenggarakan pada Rabu, 13 April 2022.
DQLab membantu terjun ke dunia data melalui talkshow “Setiap Data Punya Cerita: Berkenalan dengan Exploratory Data Analysis (EDA)”. Acara tersebut dilaksanakan secara daring, dengan mengundang pembicara Ronny Fahrudin, Data Scientist di S3 Innovate.
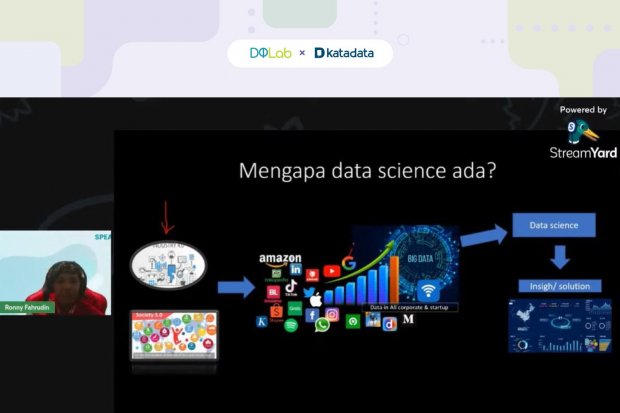
Ronny menjelaskan, data science merupakan ilmu pengetahuan interdisiplin tentang metode komputasi untuk mendapatkan informasi berharga dari sekumpulan data. Prosesnya mencakup tiga fase, yakni desain data, mengumpulkan data dan analisis data.
Dalam data science terdapat tujuh proses, yakni problem definition, data mining, data preparation, exploratory data analysis, feature engineering, model building, hingga model evaluation.
Data science pun tidak akan jauh dari Exploratory Data Analysis (EDA). “Teknologi dan manusia bisa diselaraskan, maka dari itu kita (manusia) butuh data science untuk mengolah data itu bisa menjadi insight, atau pun menjadi solusi,” kata Ronny.
Data science dianggap penting. Terlebih lagi sekarang sudah memasuki era industri 4.0 dan kehidupan mulai tidak bisa lepas dari sosial media. Setiap hari, kata dia, data-data yang berasal dari sosial media selalu tumbuh dan tidak bisa berkurang, sehingga disebut sebagai big data.
Penumpukan big data tersebut, menurut dia, harus dimanfaatkan dengan ilmu data science. Tujuannya agar big data bisa menjadi insight dan solusi. Dalam menemukan insight dan solusi dibutuhkanlah EDA.
“Bahkan di industri 5.0 nanti, teknologi dan manusia bisa diselaraskan dengan data science, salah satunya dengan EDA,” ujar Ronny.
Lebih jauh Ronny menjelaskan tentang definisi EDA. EDA adalah proses kritis dalam melakukan investigasi awal pada data untuk menemukan pola, menemukan anomali, menguji hipotesis dan memeriksa asumsi dengan bantuan statistik ringkasan dan representasi grafis (visualisasi).
EDA dibutuhkan untuk menemukan struktur atau wawasan yang tidak terduga dalam data, mengidentifikasi variabel/feature penting dalam dataset, dan menguji hipotesis atau cek asumsi-asumsi yang berhubungan dengan dataset.
Selain itu juga, EDA penting untuk mengecek kualitas data yang akan melalui cleansing process dan processing, mencari korelasi-korelasi atau sebab akibat yang ada dalam data, dan menyampaikan wawasan atau informasi tentang data kepada stakeholder.
Adapun cara menilai data yang berkualitas, menurut Ronny, perlu ada parameter dan pengecekan sejumlah hal untuk menentukan kualitas data. Data yang digunakan harus lengkap sesuai kebutuhan bisnis dan harapan, akurasi data sesuai dengan realitas dunia nyata, dan data konsisten dengan jenis sebelumnya.
Lalu juga data harus relevan dengan masa kini, tidak boleh duplikat atau harus valid, dan harus tersedia serta diketahui sumber data tersebut berasal (asal-usul dari tersebut).
Mengenai EDA, menurut Ronny, tahapan EDA paling umum bermula dari mengamati kumpulan data yang ada, mencari missing value dan membenahinya jikalau diperlukan.
Selanjutnya mengkategorikan data dan numerical, identifikasi hubungan antar variabel dan outliners, skewness data, aplikasikan statistik deskriptif dan interentials.
Adapun konsep EDA dalam Python, yakni transform dan cleaning menggunakan tools NumPy, Pandas atau Scipy.
NumPy, kata dia, berfungsi sebagai library untuk melakukan proses komputasi numerik terutama dalam bentuk array multidimensional.
Pandas digunakan untuk load data, preparing data, modelling data dan manipulation data. Sementara, Scipy digunakan untuk bekerja dengan array NumPy dan menyediakan banyak komputasi numerik yang ramah pengguna dan efisien seperti rutinitas untuk integrasi, diferensiasi dan optimasi numerik.
Untuk membandingkan data, dapat melalui visualisasi data menggunakan Matplotlib, Seaborn, Folium dan Plotly. Matplotlib digunakan untuk visualisasi data simple atau dasarnya saja.
Seaborn digunakan untuk visualisasi data yang bagus dan warna-warni, sedangkan Folium berfokus pada visualisasi data maps geografis dan Plotly bisa digunakan untuk interaktif visualisasi.
Hal tak kalah penting adalah visualisasi untuk EDA. Ronny menjelaskan, tujuan visualisasi data bar chart dan bullet chart digunakan untuk aktivitas perbandingan.
Sementara, scatterplot dan heatmap digunakan untuk korelasi, histogram dan boxplot digunakan untuk distribusi, line chart dan area chart digunakan untuk trend evaluation dan pie chart dan treemap digunakan untuk part to whole.
Secara keseluruhan, Ronny menyampaikan untuk berkarir di bidang data tentunya harus memiliki kemampuan programming knowledge dan memahami bahasa pemrograman, seperti R, Python dan lain-lain.
Pengetahuan akan data science dan EDA, bisa dipelajari bersama DQLab.
Dapatkan pengalaman membaca lebih nyaman dan nikmati fitur menarik lainnya lewat aplikasi mobile Katadata.


